statistics¶
Statistical utilities for working with CME solver output.
- class cmepy.statistics.Distribution(p=None)¶
Distributions are mappings that represent probability distributions over a discrete state space.
- compress(epsilon)¶
d.compress(epsilon) -> compressed epsilon-approximation of d
Returns compressed version of distribution.
The returned approximation is compressed, in the sense that it is the approximation with the smallest support, while the error between d and the approximation is within epsilon (L1 norm).
- covariance()¶
d.covariance() -> cov
Returns covariance of the distribution d, provided dimension == 2.
- dimension¶
- inferred dimension of state space of this distribution
- expectation()¶
d.expectation() -> mu
Returns expected state of the distribution d, provided dimension > 0.
- from_dense(p_dense, origin=None)¶
Replaces distribution using array p_dense in place
Returns self
The argument p_dense should be a numpy array of probabilities. The indices of the array are used to define the corresponding states. Multi-dimensional arrays are supported.
Optional argument origin defines the origin. This is added to the indices when defining the states.
- kl_divergence(other)¶
Returns KL divergence to the distribution other from this distribution.
The Kullback-Leibler (KL) divergence of q from p is defined as
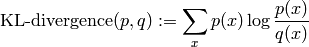
- lp_distance(other, p=1)¶
- Returns Lp distance to the distribution other. Default p = 1.
- lp_norm(p=1)¶
- Returns Lp norm of distribution. Default p = 1.
- map(f, g=None)¶
d.map(f [, g]) -> distribution
Returns a copy of the distribution d, with each key replaced by its image under f. Any duplicate image keys are merged, with the value of the merged key equal to the sum of the values.
If g is supplied, it is used instead of addition to reduce the values of duplicate image keys.
- standard_deviation()¶
d.standard_deviation() -> sigma
Returns std deviation of the Distribution d, provided dimension == 1.
- to_dense(shape, origin=None)¶
- Returns dense version of distribution for given array shape and origin
- variance()¶
d.variance() -> sigma_squared
Returns variance of the Distribution d, provided dimension == 1.
- cmepy.statistics.compress(p, epsilon)¶
compress(p, epsilon) -> compressed epsilon-approximation of p
Returns an approximation of the mapping p, treating p as a distribution p : states -> probabilities. The returned approximation is compressed, in the sense that it is the approximation with the smallest support, while the error between p and the approximation is within epsilon (L1 norm).
- cmepy.statistics.covariance(p)¶
covariance(p) -> cov
Returns the covariance cov, treating the mapping p as a distribution p : states -> probabilities.
- cmepy.statistics.expectation(p)¶
expectation(p) -> mu
Returns the expected value mu, treating the mapping p as a distribution p : states -> probabilities.
- cmepy.statistics.kl_divergence(p, q)¶
Returns KL-divergence of distribution q from distribution p.
The Kullback-Leibler (KL) divergence is defined as
Warning: this function uses numpy’s scalar floating point types to perform the evaluation. Therefore, the result may be non-finite. For example, if the state x has non-zero probability for distribution p, but zero probability for distribution q, then the result will be non-finite.
- cmepy.statistics.lp_distance(x, y, p=1)¶
Returns the Lp distance between the distributions x & y. Default p = 1.
Equivalent to lp_norm(x - y, p)
- cmepy.statistics.lp_norm(d, p=1)¶
- Returns the Lp norm of the distribution d. Default p = 1.
- cmepy.statistics.map_distribution(f, p, g=None)¶
map_distribution(f, p [, g]) -> mapping
Returns a copy of the mapping p, with each key replaced by its image under f. Any duplicate image keys are merged, with the value of the merged key equal to the sum of the values.
It is expected that f returns tuples or scalars, and behaves in a reasonable way when given vector state array arguments.
If g is supplied, it is used instead of addition to reduce the values of duplicate image keys. If given, g must have a reduce method of the form
g.reduce(probabilities) -> reduced_probability
for example, setting g to a numpy ufunc would be fine.
- cmepy.statistics.map_distribution_simple(f, p, g=None)¶
map_distribution_simple(f, p [, g]) -> mapping
reference implementation of map_distribution that is simple but slow
- cmepy.statistics.variance(p)¶
variance(p) -> sigma_squared
Returns the variance sigma_squared, treating the mapping p as a distribution p : states -> probabilities.